LLM-модели
Раздел «LLM-Модели» позволяет выбрать и настроить большую языковую модель (LLM), которая будет работать в качестве ядра вашего ИИ-агента. Здесь вы можете управлять точностью, креативностью, а также возможностью распознавания аудио, изображений и документов.
Выбор модели
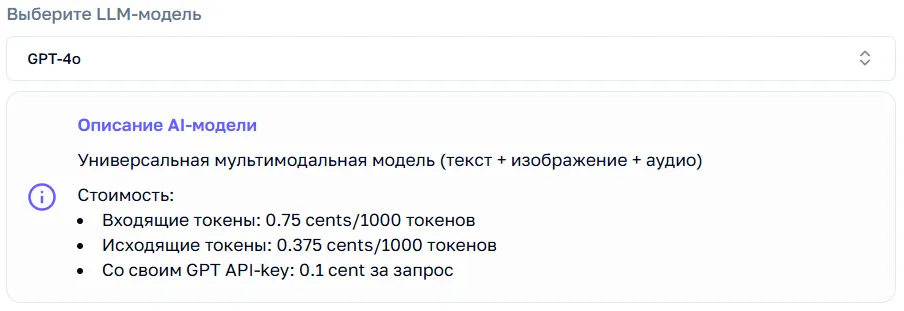
Section titled “Выбор модели”В этом разделе вы выбираете LLM-модель, которая будет использоваться агентом. После выбора вы увидите стоимость токенов, установленную создателями модели.
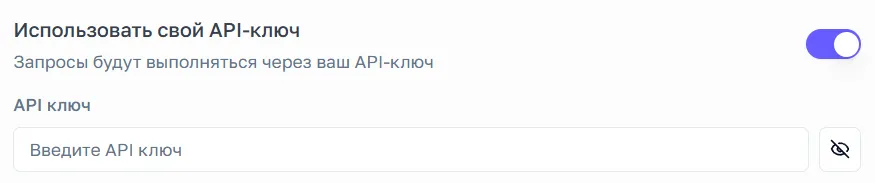
Вы можете добавить свой API ключ, если хотите снизить расходы на нашей платформе:
Настройки модели
Section titled “Настройки модели”Стандартные настройки
Section titled “Стандартные настройки”Температура 1.0 – средняя температура, обеспечивающая оптимальный баланс точности и гибкости. Агент следует скриптам, но при необходимости может проявлять инициативу. Рекомендуется для большинства сценариев использования.
Распознавать аудио Включение распознавания аудио через Whisper позволяет агенту понимать голосовые сообщения и преобразовывать их в текст для обработки.
Настройка “Распознавать изображения” включается распознавания изображений форматов JPG, PNG, JPEG. Агент сможет анализировать изображения, предоставленные пользователем, и использовать их в диалоге.
Распознавать файлы Включение распознавания документов PDF. Агент сможет извлекать текст из файлов для обработки и ответа на вопросы пользователя.
Продвинутые настройки
Section titled “Продвинутые настройки”Frequency Penalty
Section titled “Frequency Penalty”Значение от 0.0 до 1.0. Уменьшает повторение часто встречающихся слов в ответах агента. Полезно для создания более разнообразного текста.
Presence Penalty
Section titled “Presence Penalty”Значение от 0.0 до 1.0. Уменьшает повторение уже упомянутых слов в диалоге. Помогает избегать повторов и делает текст более естественным.